DeepSeek R1和DeepSeek V3 - 兩種DeepSeek輸出模型的比較
2025-01-30
DeepSeek-AI 開發了兩個令人印象深刻的人工智慧模型:DeepSeek R1 和 DeepSeek V3。每個都有不同的用途,R1 專門用於推理任務,V3 專為可擴展和高效的語言處理而設計。
本文詳細介紹了它們的功能、訓練方法和優勢,以幫助您決定哪種模型符合您的需求。

DeepSeek R1:專注於高階推理
深尋R1 是一種基於強化學習 (RL) 來處理複雜任務的推理優先模型。它有兩個版本:
DeepSeek R1-Zero 和 DeepSeek R1。這些版本共享相同的架構,但訓練方法不同。
DeepSeek R1的特點
推理能力
DeepSeek R1-零 完全使用 RL 進行訓練,沒有任何監督微調 (SFT)。這使得模型能夠獨立發展自我反思和驗證等高階推理功能。然而,R1-Zero 面臨重複輸出和可讀性不一致等問題。
為了解決這些問題,DeepSeek R1 在 RL 之前加入了 SFT 階段。這一步驟提高了模型的清晰度和準確性,使其成為推理任務的更可靠的選擇。
培訓方法
R1 的訓練過程著重於思想鏈 (CoT) 推理,這有助於模型將問題分解為更小、更易於管理的步驟。
CoT 方法使 R1 在數學、編碼和邏輯推理等領域非常有效。
績效指標
DeepSeek R1 在需要邏輯思維的基準測試中表現異常出色。例如:
它在 DROP(92.2% F1 分數)和 AIME 2024(79.8% pass@1)等任務中優於 OpenAI 的 o1-mini。
R1-Distill-Qwen-32B 等蒸餾版本可透過明顯較少的參數提供可比較的結果,從而更適合較小規模的應用。
DeepSeek R1的應用
深尋R1 非常適合需要深度推理的任務,例如學術研究、解決問題的應用程式和決策支援系統。
由於其開源可用性,研究人員還可以針對特定領域進行微調。
DeepSeek V3:平衡效率和可擴展性
深思V3 採用不同的方法,專注於可擴展性和高效處理。
它建立在專家混合 (MoE) 架構之上,其中每個令牌僅啟動其參數的子集,從而在不犧牲效能的情況下降低計算成本。
DeepSeek V3的特點
高效架構
DeepSeek V3 使用 MoE 架構,每個令牌啟動 671B 參數中的 37B 參數。
這種選擇性活化可確保模型高效運行,在推理過程中需要更少的資源。
培訓效率
V3 的訓練過程旨在具有成本效益。採用混合精準度FP8訓練,減少大規模預訓練所需的GPU小時數。
例如,在 14.8 兆個代幣上訓練 V3 僅需要 278.8 萬 H800 GPU 小時,與其他大型模型相比更經濟。
基準表現
深思V3 擅長數學和多語言任務。例如:
它在 CMath 上獲得了 90.7% 的分數,在 HumanEval 上的編碼任務上獲得了 65.2% pass@1 的成績。
在 CLUEWSC 和 C-Eval 等中文基準測試中,V3 展現了卓越的準確性,超越了許多競爭對手。
多標記預測 (MTP)
DeepSeek V3 引入了 MTP,該功能允許它同時預測多個令牌。這加快了推理速度並有助於提高其整體效率。
DeepSeek V3的應用
DeepSeek V3 非常適合大規模自然語言處理 (NLP) 任務,例如 對話式人工智慧、多語言翻譯和內容生成。
它的效率使其成為尋求大規模部署人工智慧的組織的絕佳選擇。
DeepSeek R1 與 DeepSeek V3: 比較 DeepSeek R1 和 DeepSeek V3
雖然這兩種型號都提供了令人印象深刻的功能,但它們的差異使它們適用於不同的用例。
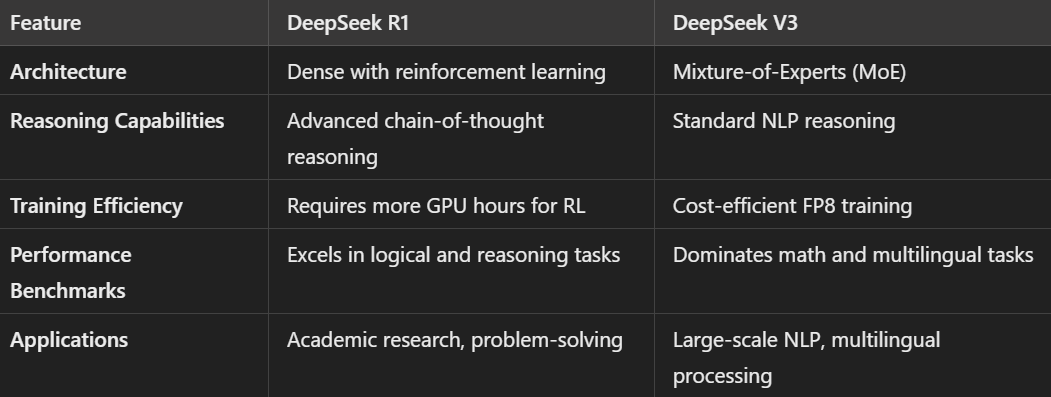
DeepSeek R1 在推理繁重的任務中脫穎而出,透過其基於 RL 的管道提供高級邏輯。
同時,DeepSeek V3 憑藉其可擴展且高效的設計,在計算要求較高的任務中表現出色。
DEEPSEEKAI 代幣免責聲明
儘管 DeepSeek AI 技術 正在改變行業,重要的是要澄清它與現有行業的關係(或缺乏關係) DEEPSEEKAI 代幣 在加密貨幣市場。
該代幣由社群創建,受到 DeepSeek 產品的啟發,但 與公司沒有正式隸屬關係。
DEEPSEEKAI 代幣 是一項由粉絲驅動的倡議,雖然它共享名稱,但並不代表 DeepSeek 的技術或服務。
投資者和加密貨幣愛好者應保持謹慎,並了解該代幣與 DeepSeek AI 或其生態系統沒有直接聯繫。
對於DeepSeek的準確更新和訊息,用戶應依賴官方管道,不要將產品與第三方代幣關聯。

結論
DeepSeek R1 和 DeepSeek V3 之間的選擇取決於您的特定需求。如果您正在尋找可以處理推理繁重任務的模型,DeepSeek R1 是您的最佳選擇 更好的選擇。
它分解複雜問題並提供清晰推理的能力使其對於研究和學術應用具有無價的價值。
另一方面,如果您的重點是大規模 NLP 任務或多語言應用程序,DeepSeek V3 可以提供無與倫比的效率和效能。
其可擴展的架構和經濟高效的培訓使其成為需要強大人工智慧解決方案的組織的絕佳選擇。
兩種型號均代表 重大進步 在人工智慧開發方面。透過了解他們的優勢和能力,您可以就哪種模型最適合您的目標做出明智的決定。
常見問題解答
1. DeepSeek R1和V3的主要差異是什麼?
DeepSeek R1 專注於使用強化學習的推理任務,而 DeepSeek V3 則專注於透過其 Mixture-of-Experts 架構進行可擴展且高效的自然語言處理。
2. 哪一種模型的訓練成本效益較高?
由於其混合精準度 FP8 訓練框架,DeepSeek V3 更具成本效益,需要更少的 GPU 時間。
3. 兩種型號都可以本地部署嗎?
是的,DeepSeek R1和V3都支援本地部署,並提供硬體和軟體配置的詳細說明。
投資者註意事項
儘管加密貨幣炒作令人興奮,但請記住,加密貨幣空間可能會不穩定。始終進行研究,評估您的風險承受能力,並考慮任何投資的長期潛力。
比真官方網站:
報名: https://www.bitrue.com/user/register
免責聲明:所表達的觀點僅屬於作者本人,不代表本平台觀點。本平台及其關聯公司對所提供資訊的準確性或適用性不承擔任何責任。它僅供參考,不作為財務或投資建議。
免責聲明:本文內容不構成財務或投資建議。



