DeepSeek R1과 DeepSeek V3 - 두 가지 DeepSeek 출력 모델 비교
2025-01-30
DeepSeek-AI DeepSeek R1과 DeepSeek V3라는 두 가지 인상적인 AI 모델을 개발했습니다. 각각은 추론 작업을 전문으로 하는 R1과 확장 가능하고 효율적인 언어 처리를 위해 설계된 V3 등 서로 다른 목적을 수행합니다.
이 문서에서는 귀하의 요구 사항에 맞는 모델을 결정하는 데 도움이 되도록 기능, 훈련 방법 및 강점을 분석합니다.

DeepSeek R1: 고급 추론에 중점
딥시크 R1 복잡한 작업을 처리하기 위해 강화 학습(RL)을 기반으로 하는 추론 우선 모델입니다. 두 가지 버전으로 제공됩니다.
DeepSeek R1-Zero 및 DeepSeek R1. 이러한 버전은 동일한 아키텍처를 공유하지만 학습 접근 방식이 다릅니다.
DeepSeek R1의 특징
추론 능력
DeepSeek R1-제로 SFT(Supervised Fine-Tuning) 없이 RL을 사용하여 완전히 훈련되었습니다. 이를 통해 모델은 자기 성찰 및 검증과 같은 고급 추론 기능을 독립적으로 개발할 수 있었습니다. 그러나 R1-Zero는 반복적인 출력 및 일관되지 않은 가독성과 같은 문제에 직면했습니다.
이러한 문제를 해결하기 위해 DeepSeek R1은 RL 앞에 SFT 단계를 추가했습니다. 이 단계를 통해 모델의 명확성과 정확성이 향상되어 추론 작업을 위한 보다 안정적인 옵션이 되었습니다.
훈련 방법론
R1의 교육 프로세스는 모델이 문제를 더 작고 관리하기 쉬운 단계로 나누는 데 도움이 되는 사고 사슬(CoT) 추론에 중점을 둡니다.
CoT 접근 방식은 수학, 코딩, 논리적 추론과 같은 영역에서 R1을 매우 효과적으로 만듭니다.
성능 지표
DeepSeek R1은 논리적 사고가 필요한 벤치마크에서 탁월한 성능을 발휘합니다. 예를 들어:
DROP(92.2% F1 점수) 및 AIME 2024(79.8% pass@1)와 같은 작업에서 OpenAI의 o1-mini보다 성능이 뛰어납니다.
R1-Distill-Qwen-32B와 같은 증류 버전은 훨씬 적은 매개변수로 비슷한 결과를 제공하므로 소규모 애플리케이션에서 더 쉽게 접근할 수 있습니다.
DeepSeek R1의 응용
딥시크 R1 학술 연구, 문제 해결 애플리케이션, 의사결정 지원 시스템 등 심층적인 추론이 필요한 작업에 이상적입니다.
연구원들은 오픈 소스 가용성으로 인해 특정 도메인에 맞게 이를 미세 조정할 수도 있습니다.
DeepSeek V3: 효율성과 확장성의 균형
딥시크 V3 확장성과 효율적인 처리에 중점을 두어 다른 접근 방식을 취합니다.
MoE(Mixture-of-Experts) 아키텍처를 기반으로 구축되어 각 토큰에 대해 매개변수의 하위 집합만 활성화되어 성능 저하 없이 계산 비용을 절감합니다.
DeepSeek V3의 특징
효율적인 아키텍처
DeepSeek V3는 각 토큰에 대해 총 671B 매개변수 중 37B 매개변수를 활성화하는 MoE 아키텍처를 사용합니다.
이러한 선택적 활성화를 통해 모델이 효율적으로 작동하고 추론 중에 더 적은 리소스가 필요합니다.
훈련 효율성
V3의 교육 과정은 비용 효율적으로 설계되었습니다. 대규모 사전 훈련에 필요한 GPU 시간을 줄이는 혼합 정밀도 FP8 훈련을 채택합니다.
예를 들어, 14조 8천억 개의 토큰에 대한 V3 교육에는 H800 GPU 시간이 27억 8800만 시간만 필요하므로 다른 대형 모델에 비해 경제적입니다.
벤치마크 성능
딥시크 V3 수학 및 다국어 작업에 탁월합니다. 예를 들어:
코딩 작업에 대해 CMath에서 90.7% 점수, HumanEval에서 65.2% pass@1을 달성했습니다.
CLUEWSC 및 C-Eval과 같은 중국어 벤치마크에서 V3는 놀라운 정확도를 보여 많은 경쟁사를 능가했습니다.
다중 토큰 예측(MTP)
DeepSeek V3에는 여러 토큰을 동시에 예측할 수 있는 기능인 MTP가 도입되었습니다. 이는 추론 속도를 높이고 전반적인 효율성에 기여합니다.
DeepSeek V3의 응용
DeepSeek V3는 다음과 같은 대규모 자연어 처리(NLP) 작업에 매우 적합합니다. 대화형 AI, 다국어 번역 및 콘텐츠 생성.
효율성이 뛰어나 AI를 대규모로 배포하려는 조직에 탁월한 선택입니다.
DeepSeek R1 대 DeepSeek V3: DeepSeek R1과 DeepSeek V3 비교
두 모델 모두 인상적인 기능을 제공하지만 차이점으로 인해 다양한 사용 사례에 적합합니다.
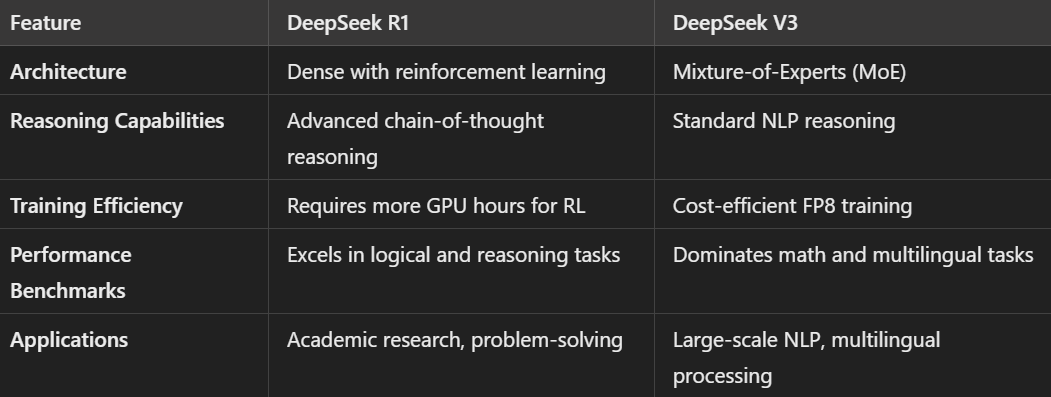
DeepSeek R1은 RL 기반 파이프라인을 통해 고급 논리를 제공하여 추론이 많은 작업에서 두각을 나타냅니다.
한편 DeepSeek V3는 확장 가능하고 효율적인 디자인 덕분에 계산량이 많은 작업에서 빛을 발합니다.
DEEPSEEKAI 토큰 면책조항
하는 동안 DeepSeek AI의 기술 산업을 변화시키고 있는 경우, 기존 산업과의 관계(또는 관계 부족)를 명확히 하는 것이 중요합니다. DEEPSEEKAI 토큰 암호화폐 시장에서.
커뮤니티에서 생성된 이 토큰은 DeepSeek의 제품에서 영감을 얻었지만 회사와 공식적으로 제휴하지 않음.
DEEPSEEKAI 토큰 팬 중심의 이니셔티브이며 이름을 공유하지만 DeepSeek의 기술이나 서비스를 대표하지는 않습니다.
투자자와 암호화폐 애호가는 토큰이 DeepSeek AI 또는 해당 생태계와 직접적인 관련이 없다는 점을 주의하고 이해해야 합니다.
DeepSeek에 대한 정확한 업데이트 및 정보를 얻으려면 사용자는 공식 채널에 의존해야 하며 제품을 제3자 토큰과 연결해서는 안 됩니다.

결론
DeepSeek R1과 DeepSeek V3 중에서 선택하는 것은 특정 요구 사항에 따라 다릅니다. 추론이 많은 작업을 처리할 수 있는 모델을 찾고 있다면 DeepSeek R1이 적합합니다. 더 나은 옵션.
복잡한 문제를 분석하고 명확한 추론을 제공하는 능력은 연구 및 학술 응용에 매우 중요합니다.
반면, 대규모 NLP 작업이나 다국어 애플리케이션에 중점을 두는 경우 DeepSeek V3는 비교할 수 없는 효율성과 성능을 제공합니다.
확장 가능한 아키텍처와 비용 효율적인 교육 덕분에 강력한 AI 솔루션이 필요한 조직에 탁월한 선택이 됩니다.
두 모델 모두 대표 중요한 발전 AI 개발 중. 각 모델의 강점과 역량을 이해하면 어떤 모델이 귀하의 목표에 가장 적합한지 정보에 근거한 결정을 내릴 수 있습니다.
자주 묻는 질문
1. DeepSeek R1과 V3의 주요 차이점은 무엇입니까?
DeepSeek R1은 강화 학습을 사용한 추론 작업을 전문으로 하는 반면, DeepSeek V3은 Mixture-of-Experts 아키텍처를 통해 확장 가능하고 효율적인 자연어 처리에 중점을 둡니다.
2. 어떤 모델이 훈련하기에 더 비용 효율적인가요?
DeepSeek V3는 혼합 정밀도 FP8 훈련 프레임워크 덕분에 더 적은 GPU 시간을 필요로 하여 더욱 비용 효율적입니다.
3. 두 모델 모두 로컬로 배포할 수 있나요?
예, DeepSeek R1과 V3 모두 로컬 배포를 지원하며 하드웨어 및 소프트웨어 구성에 대한 자세한 지침이 제공됩니다.
투자자 주의
암호화폐에 대한 과대광고는 흥미로웠지만 암호화폐 공간은 변동성이 클 수 있다는 점을 기억하세요. 항상 연구를 수행하고, 위험 허용 범위를 평가하고, 투자의 장기적인 잠재력을 고려하십시오.
Bitrue 공식 웹사이트:
웹사이트: https://www.bitrue.com/
가입: https://www.bitrue.com/user/register
면책 조항: 표현된 견해는 전적으로 작성자의 것이며 이 플랫폼의 견해를 반영하지 않습니다. 이 플랫폼과 그 계열사는 제공된 정보의 정확성이나 적합성에 대해 어떠한 책임도 지지 않습니다. 이는 정보 제공의 목적으로만 제공되며 재정 또는 투자 조언을 제공하기 위한 것이 아닙니다.
면책 조항: 이 기사 내용은 재정 또는 투자 조언을 구성하지 않습니다.



