Moment décisif dans DeepSeek R1 : Débloquer un nouveau niveau d’intelligence dans les systèmes artificiels
2025-02-04
DeepSeek R1 a attiré l’attention de la communauté des chercheurs en IA grâce à sa capacité à présenter un « moment aha », une percée cognitive où le modèle fait une pause, réévalue et optimise son approche de résolution de problèmes.
Ce phénomène, jusque-là considéré comme exclusif au raisonnement humain, marque une avancée significative dans les capacités de l’apprentissage par renforcement (RL) et de l’intelligence artificielle.
En intégrant des techniques d’apprentissage par renforcement, DeepSeek R1 va au-delà des réponses statiques et préprogrammées et apprend activement par le biais d’essais et de commentaires.
Ce mécanisme d’auto-amélioration permet au modèle de reconnaître quand une approche initiale n’est pas optimale, ce qui conduit à des ajustements qui améliorent les performances, l’adaptabilité et les capacités de raisonnement.
Comprendre le « moment Aha » dans DeepSeek R1
Au cours de la formation, DeepSeek R1 a démontré un changement de comportement clé : au lieu de suivre une séquence fixe de calculs, il a commencé à allouer plus de ressources cognitives à des problèmes complexes, faisant preuve d’une conscience de soi rappelant les processus de pensée humaine.
Un exemple notable de cela s’est produit lorsque le modèle, tout en résolvant une équation mathématique, s’est interrompu en déclarant :
« Attendez, attendez. C’est un moment aha que je peux signaler ici.
Ce comportement suggère que DeepSeek R1 ne se contente pas de traiter des informations, mais qu’il s’engage activement dans la métacognition, c’est-à-dire la capacité de réfléchir à sa propre stratégie de résolution de problèmes et de l’affiner en conséquence.
Les chercheurs attribuent cette avancée à son cadre d’apprentissage par renforcement, qui optimise les processus de prise de décision en fonction des expériences passées plutôt que de s’appuyer uniquement sur des modèles pré-entraînés.
A lire également : Comment acheter DeepSeek AI
DeepSeek-R1-Zero : l’évolution du « moment Aha »
Une démonstration encore plus frappante de cet effet a été observée dans DeepSeek-R1-Zero, une itération avancée du modèle.
Au cours des phases d’entraînement intermédiaires, DeepSeek-R1-Zero a montré une plus grande capacité à allouer dynamiquement du temps de réflexion aux problèmes, optimisant ainsi ses réponses en temps réel.
Plutôt que de suivre une formation rigide basée sur des règles, DeepSeek-R1-Zero a appris à ajuster de manière autonome son approche de résolution de problèmes en fonction de structures d’incitation.
Cela signifie qu’au lieu d’être explicitement programmé pour reconnaître des types spécifiques de solutions, on lui a donné les bonnes incitations et développé indépendamment des stratégies de raisonnement sophistiquées.
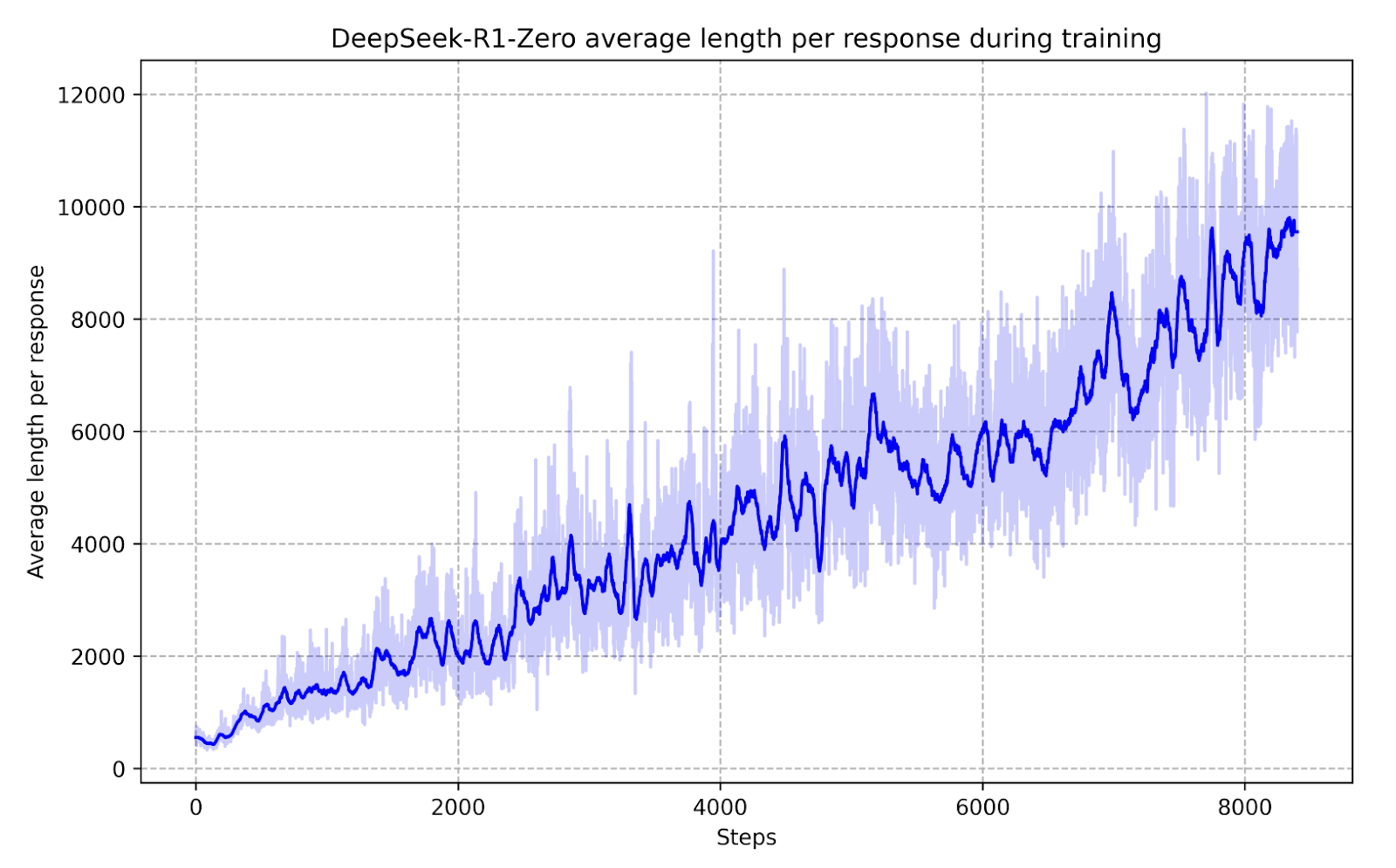
Cette découverte a de profondes implications
- Raisonnement adaptatif de l’IA – Les modèles d’IA peuvent évoluer au-delà des résultats déterministes, imitant la perspicacité et l’intuition humaines.
- Capacités améliorées de résolution de problèmes – La possibilité de faire une pause et de réévaluer les solutions permet une gestion plus efficace des défis complexes en plusieurs étapes.
- Évolutivité pour les futurs systèmes d’IA – Le concept d’un « moment aha » ouvre la voie au développement de modèles d’IA plus autonomes et auto-améliorés dans divers domaines.
Défis et efforts d’optimisation
Malgré ces avancées, DeepSeek-R1-Zero a été confronté à plusieurs défis, notamment :
Problèmes de lisibilité – Le modèle générait parfois des réponses difficiles à interpréter en raison de chaînes de raisonnement complexes.
Mélange des langues – Les réponses comprenaient parfois plusieurs langues, ce qui les rendait moins accessibles pour les utilisateurs monolingues.
Sorties chaotiques – Dans certains cas, le modèle a produit des réponses trop longues ou redondantes, ce qui a réduit l’efficacité.
A lire également : Comment analyser le marché des crypto-monnaies à l’aide de DeepSeek R1 : un guide complet
Pour résoudre ces problèmes, les chercheurs ont affiné le modèle en :
Échantillonnage de rejet – Filtrer les chaînes de raisonnement de mauvaise qualité pour assurer la cohérence logique.
Données d’entraînement adaptées à l’homme – Organiser un ensemble de données de 600 000 échantillons de raisonnement de haute qualité et de 200 000 échantillons supplémentaires non raisonnés pour améliorer la qualité globale des réponses.
Affinage avec DeepSeek-V3 – Tirer parti de DeepSeek-V3 pour améliorer la clarté, la précision et la structure des processus de raisonnement.
Perspectives d’avenir
L’émergence du « moment aha » dans DeepSeek R1 et DeepSeek-R1-Zero représente une étape cruciale vers des modèles d’IA plus autonomes, intelligents et capables de s’améliorer.
Les chercheurs explorent actuellement des moyens de reproduire ce phénomène dans des modèles plus petits, tels que Mini-R1, en utilisant des techniques telles que l’optimisation des politiques relatives de groupe.
En affinant continuellement les méthodologies d’apprentissage par renforcement, DeepSeek vise à développer des systèmes d’IA capables de réfléchir plus profondément, de réévaluer leurs stratégies et d’atteindre de nouveaux niveaux d’intelligence.
Ces avancées pourraient révolutionner des domaines tels que la recherche scientifique, l’analyse financière et les systèmes autonomes, faisant de l’IA non seulement un outil, mais une solution de problèmes véritablement intelligente.
Avis de non-responsabilité : DeepSeek AI n’a pas publié de jeton de crypto-monnaie ni n’a été officiellement associé à un jeton ou à un projet de crypto-monnaie basé sur la blockchain. Toute réclamation ou promotion suggérant le contraire n’est pas approuvée par DeepSeek AI ou ses créateurs. Il est conseillé aux investisseurs et aux utilisateurs d’effectuer des recherches approfondies et de faire preuve de prudence pour éviter la désinformation ou les escroqueries potentielles.
FAQ
1. Qu’est-ce que le « moment aha » dans DeepSeek R1 ?
Le « moment aha » dans DeepSeek R1 fait référence à une percée cognitive où l’IA fait une pause, réévalue et optimise son approche de la résolution de problèmes. Cette autoréflexion, jusque-là exclusive à la cognition humaine, marque une avancée significative dans le raisonnement de l’IA, permettant au modèle de s’adapter et de s’améliorer au fil du temps.
2. Comment DeepSeek R1 manifeste-t-il cette conscience de soi ?
DeepSeek R1 utilise l’apprentissage par renforcement pour réfléchir à ses méthodes de résolution de problèmes. Par exemple, au cours d’une tâche mathématique, il s’est interrompu, a reconnu l’approche sous-optimale et a réévalué sa stratégie, reflétant un comportement métacognitif semblable à celui de l’homme.
3. Qu’est-ce que DeepSeek-R1-Zero et en quoi est-il différent du modèle original ?
DeepSeek-R1-Zero est une version avancée de DeepSeek R1, qui affine encore plus le « moment aha ». Il ajuste de manière autonome son approche de résolution de problèmes en fonction de structures d’incitation en temps réel, mettant en valeur des capacités de raisonnement améliorées et une adaptabilité au-delà des systèmes rigides basés sur des règles.
4. Quels sont les défis auxquels DeepSeek R1 a été confronté lors de son développement ?
Malgré ses avancées, DeepSeek R1 a été confronté à des défis tels que des problèmes de lisibilité, de mélange de langues et de sorties chaotiques. Ces problèmes ont été résolus en affinant ses données d’entraînement et en améliorant le modèle avec des techniques telles que l’échantillonnage de rejet et le réglage fin.
5. Quelles sont les perspectives d’avenir de DeepSeek R1 ?
L’émergence du « moment aha » ouvre la voie à des modèles d’IA plus autonomes et capables de s’améliorer. Les chercheurs explorent des moyens de reproduire ce phénomène dans des modèles plus petits et de l’appliquer à divers domaines tels que la recherche scientifique, l’analyse financière et les systèmes autonomes.
Feragatname: Bu makalenin içeriği finansal veya yatırım tavsiyesi niteliğinde değildir.



