DeepSeek R1 and DeepSeek V3 - Comparing Two DeepSeek Output Models
2025-01-30
DeepSeek-AI has developed two impressive AI models: DeepSeek R1 and DeepSeek V3. Each serves a different purpose, with R1 specialising in reasoning tasks and V3 designed for scalable and efficient language processing.
This article breaks down their features, training methods, and strengths to help you decide which model aligns with your needs.

DeepSeek R1: A Focus on Advanced Reasoning
DeepSeek R1 is a reasoning-first model that builds on reinforcement learning (RL) to handle complex tasks. It comes in two versions:
DeepSeek R1-Zero and DeepSeek R1. These versions share the same architecture but differ in their training approach.
Features of DeepSeek R1
Reasoning Capabilities
DeepSeek R1-Zero was trained entirely using RL without any supervised fine-tuning (SFT). This allowed the model to independently develop advanced reasoning features like self-reflection and verification. However, R1-Zero faced issues like repetitive outputs and inconsistent readability.
To address these issues, DeepSeek R1 added an SFT stage before RL. This step improved the model’s clarity and accuracy, making it a more reliable option for reasoning tasks.
Training Methodology
The training process for R1 focuses on chain-of-thought (CoT) reasoning, which helps the model break down problems into smaller, more manageable steps.
The CoT approach makes R1 highly effective in areas like mathematics, coding, and logical reasoning.
Performance Metrics
DeepSeek R1 performs exceptionally well on benchmarks requiring logical thinking. For example:
It outperforms OpenAI’s o1-mini in tasks like DROP (92.2% F1 score) and AIME 2024 (79.8% pass@1).
Distilled versions, like R1-Distill-Qwen-32B, provide comparable results with significantly fewer parameters, making them more accessible for smaller-scale applications.
Applications of DeepSeek R1
DeepSeek R1 is ideal for tasks requiring deep reasoning, such as academic research, problem-solving applications, and decision-support systems.
Researchers can also fine-tune it for specific domains due to its open-source availability.
DeepSeek V3: Balancing Efficiency and Scalability
DeepSeek V3 takes a different approach by focusing on scalability and efficient processing.
It is built on a Mixture-of-Experts (MoE) architecture, where only a subset of its parameters is activated for each token, reducing computational costs without sacrificing performance.
Features of DeepSeek V3
Efficient Architecture
DeepSeek V3 uses MoE architecture, which activates 37B parameters out of its total of 671B for each token.
This selective activation ensures the model operates efficiently, requiring fewer resources during inference.
Training Efficiency
V3’s training process is designed to be cost-effective. It adopts mixed-precision FP8 training, which reduces the GPU hours needed for large-scale pre-training.
For example, training V3 on 14.8 trillion tokens required just 2.788M H800 GPU hours, making it more economical compared to other large models.
Performance on Benchmarks
DeepSeek V3 excels in mathematical and multilingual tasks. For instance:
It achieved a 90.7% score on CMath and a 65.2% pass@1 on HumanEval for coding tasks.
In Chinese-language benchmarks like CLUEWSC and C-Eval, V3 demonstrated remarkable accuracy, outperforming many competitors.
Multi-Token Prediction (MTP)
DeepSeek V3 introduces MTP, a feature that allows it to predict multiple tokens simultaneously. This speeds up inference and contributes to its overall efficiency.
Applications of DeepSeek V3
DeepSeek V3 is well-suited for large-scale natural language processing (NLP) tasks, such as conversational AI, multilingual translation, and content generation.
Its efficiency makes it an excellent choice for organisations looking to deploy AI at scale.
DeepSeek R1 vs DeepSeek V3
While both models offer impressive capabilities, their differences make them suitable for different use cases.
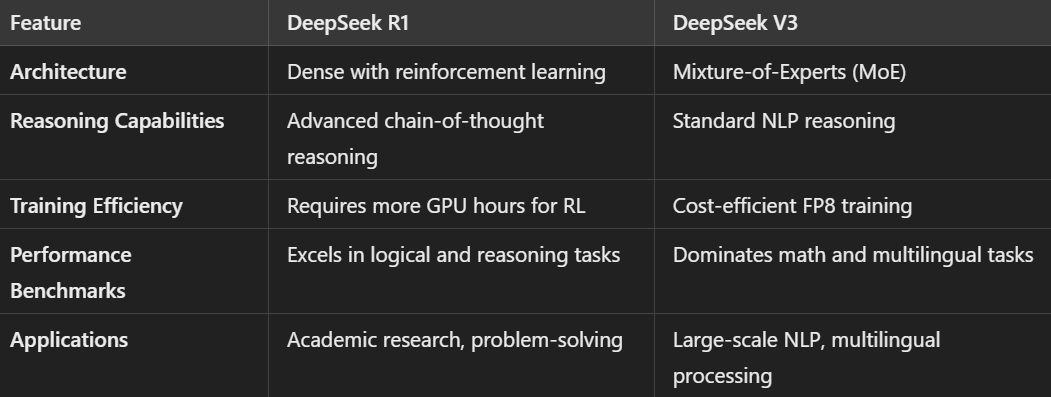
DeepSeek R1 stands out in reasoning-heavy tasks, offering advanced logic through its RL-based pipeline.
Meanwhile, DeepSeek V3 shines in computationally demanding tasks, thanks to its scalable and efficient design.
DEEPSEEKAI Token Disclaimer
While DeepSeek AI’s technology is transforming industries, it’s important to clarify its relationship—or lack thereof—with the existing DEEPSEEKAI token in the crypto market.
This token, created by the community, is inspired by DeepSeek’s products but is not officially affiliated with the company.
The DEEPSEEKAI token is a fan-driven initiative, and while it shares the name, it does not represent DeepSeek’s technology or services.
Investors and crypto enthusiasts should be cautious and understand that the token has no direct connection to DeepSeek AI or its ecosystem.
For accurate updates and information about DeepSeek, users should rely on official channels and not associate the product with third-party tokens.

Conclusion
Choosing between DeepSeek R1 and DeepSeek V3 depends on your specific needs. If you’re looking for a model that can handle reasoning-heavy tasks, DeepSeek R1 is the better option.
Its ability to break down complex problems and provide clear reasoning makes it invaluable for research and academic applications.
On the other hand, if your focus is on large-scale NLP tasks or multilingual applications, DeepSeek V3 offers unmatched efficiency and performance.
Its scalable architecture and cost-effective training make it an excellent choice for organisations requiring robust AI solutions.
Both models represent significant advancements in AI development. By understanding their strengths and capabilities, you can make an informed decision about which model best suits your goals.
Frequently Asked Questions
1. What are the main differences between DeepSeek R1 and V3?
DeepSeek R1 specialises in reasoning tasks using reinforcement learning, while DeepSeek V3 focuses on scalable and efficient natural language processing with its Mixture-of-Experts architecture.
2. Which model is more cost-efficient to train?
DeepSeek V3 is more cost-efficient, requiring fewer GPU hours thanks to its mixed-precision FP8 training framework.
3. Can both models be deployed locally?
Yes, both DeepSeek R1 and V3 support local deployment, with detailed instructions available for hardware and software configurations.
Investor Caution
While the crypto hype has been exciting, remember that the crypto space can be volatile. Always conduct your research, assess your risk tolerance, and consider the long-term potential of any investment.
Bitrue Official Website:
Website: https://www.bitrue.com/
Sign Up: https://www.bitrue.com/user/register
Disclaimer: The views expressed belong exclusively to the author and do not reflect the views of this platform. This platform and its affiliates disclaim any responsibility for the accuracy or suitability of the information provided. It is for informational purposes only and not intended as financial or investment advice.
Disclaimer: The content of this article does not constitute financial or investment advice.



