Understanding DeepSeek R1 and Its Approach to AI Reasoning
2025-01-29
Artificial intelligence has made significant progress in many areas, from language generation to image recognition.
However, reasoning remains a challenge. Many AI models can process information quickly and recognize patterns, but they struggle with tasks that require logical thinking and problem-solving.
DeepSeek R1 is a model designed to address this issue. Instead of relying entirely on human-provided answers to improve its reasoning skills, it uses reinforcement learning.
The development of DeepSeek R1 raises several questions: Can reinforcement learning be an effective way to teach AI reasoning? How does it compare to traditional training methods? And what are its strengths and limitations?

Reinforcement Learning and Its Role in AI
Most AI models are trained using supervised learning, meaning they are fed large datasets where the correct answers are already provided.
This allows them to recognize patterns and mimic human-like responses, but it does not necessarily mean they understand how to reason through problems on their own.
Reinforcement learning takes a different approach. Instead of learning from predefined answers, the AI model is placed in a trial-and-error environment where it receives feedback based on its performance. Over time, the model adjusts its approach to maximize correct responses.
DeepSeek R1 began as an experiment to see if reinforcement learning alone could develop reasoning skills.
The first version, DeepSeek R1-Zero, was trained without any supervised fine-tuning. The model learned purely through reinforcement, improving its ability to solve problems by receiving rewards for correct answers.
Source: DeepSeek
This approach led to interesting results. DeepSeek R1-Zero demonstrated strong problem-solving skills in areas like math and coding.
However, it also had some noticeable weaknesses. Some of its answers were difficult to understand, and it occasionally mixed multiple languages in the same response.
To address these issues, DeepSeek refined the model by introducing a small amount of supervised learning before the reinforcement learning process.
This resulted in DeepSeek R1, which maintained the reasoning skills developed by R1-Zero while improving readability and accuracy.
How DeepSeek R1 Compares to Other AI Models
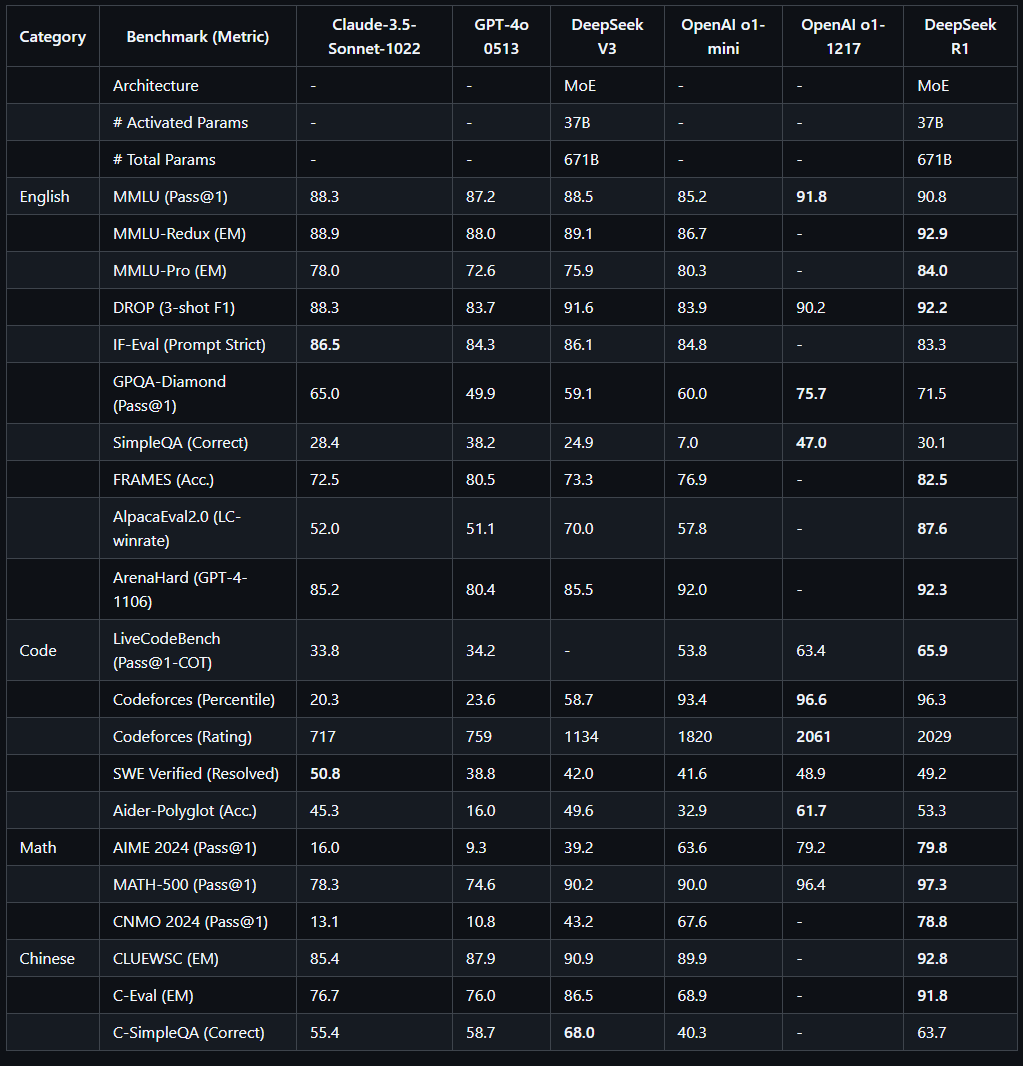
DeepSeek R1 has been tested against other AI models in a variety of reasoning tasks. These include mathematical problem-solving, coding challenges, and logical reasoning exercises.
In many cases, DeepSeek R1 has performed at a level similar to OpenAI’s o1 model, which is known for its strong reasoning abilities.
One of the unique aspects of DeepSeek R1 is how it adjusts the amount of effort it puts into solving different problems.
Instead of following a fixed number of reasoning steps for every question, the model adapts its approach depending on the complexity of the task. This allows it to spend more time on difficult questions while using less effort on simpler ones.
For example, in a mathematics benchmark called AIME 2024, DeepSeek R1 achieved a high accuracy rate, demonstrating strong problem-solving skills.
Similarly, in coding challenges such as Codeforces, the model performed well, showing its ability to handle structured problem-solving.
These results suggest that reinforcement learning can be an effective way to develop reasoning abilities in AI models. However, it also highlights that reinforcement learning alone is not always enough.
The addition of supervised fine-tuning played an important role in improving DeepSeek R1’s output quality.

Challenges and Limitations of Reinforcement Learning
While reinforcement learning has proven useful in developing AI reasoning, it also comes with challenges. One of the biggest issues is consistency.
Because the model learns by trial and error, there is always a risk that it develops reasoning patterns that work well in training but do not generalize to new problems.
Another challenge is the readability of responses. The first version of DeepSeek R1, trained purely with reinforcement learning, sometimes produced responses that were unclear or difficult to interpret. This problem had to be addressed by introducing a stage of supervised training.
Additionally, while reinforcement learning can help AI models develop logical thinking, it does not provide human-like understanding.
DeepSeek R1 still relies on patterns in data rather than true comprehension. It can solve problems based on learned strategies, but it does not "think" in the way a person would.
These challenges show that while reinforcement learning is a valuable tool, it may not be the only solution needed to create AI systems with strong reasoning abilities. A combination of different training methods might be the best approach.
Future Implications and Considerations
The development of DeepSeek R1 raises broader questions about how AI models should be trained in the future. Traditionally, AI development has been focused on using large amounts of supervised data to train models. DeepSeek’s approach suggests that reinforcement learning could be a viable alternative, at least for improving reasoning skills.
If reinforcement learning continues to prove effective, it could reduce the need for massive datasets and the expensive computational resources required to train AI models.
This could make AI research more accessible to smaller organizations and research groups that do not have the same resources as large companies.
At the same time, reinforcement learning is still a developing field and more research is needed to understand its full potential and limitations.
While DeepSeek R1 has shown promising results, it is not yet clear whether reinforcement learning alone can consistently match or surpass traditional training methods.
For AI researchers and developers, this means that the best approach may be a combination of both methods—using supervised learning for clarity and accuracy while incorporating reinforcement learning to improve reasoning and problem-solving.

Conclusion
DeepSeek R1 represents an attempt to improve AI reasoning through reinforcement learning rather than relying entirely on supervised training. The model has shown strong performance in problem-solving tasks such as mathematics and coding, demonstrating that reinforcement learning can help AI develop logical thinking skills.
However, the approach is not without challenges. Reinforcement learning introduces issues related to consistency and readability, and it does not eliminate the need for some level of supervised training.
As research in AI continues, reinforcement learning may play a larger role in shaping how AI systems learn to process and analyze information.
Frequently Asked Questions
1. How is DeepSeek R1 different from other AI models?
DeepSeek R1 uses reinforcement learning to develop reasoning skills, whereas most AI models rely primarily on supervised training. This approach allows it to learn through trial and error rather than being given predefined answers.
2. What types of tasks does DeepSeek R1 perform well in?
DeepSeek R1 has been tested on math problems, coding challenges, and logical reasoning tasks. It has performed well in these areas, achieving results comparable to OpenAI’s o1 model.
3. Does DeepSeek R1 completely replace the need for supervised training?
No. While the first version, DeepSeek R1-Zero, relied only on reinforcement learning, the updated DeepSeek R1 includes some supervised training to improve readability and response quality.
Investor Caution
While the crypto hype has been exciting, remember that the crypto space can be volatile. Always conduct your research, assess your risk tolerance, and consider the long-term potential of any investment.
Bitrue Official Website:
Website: https://www.bitrue.com/
Sign Up: https://www.bitrue.com/user/register
Disclaimer: The views expressed belong exclusively to the author and do not reflect the views of this platform. This platform and its affiliates disclaim any responsibility for the accuracy or suitability of the information provided. It is for informational purposes only and not intended as financial or investment advice.
Disclaimer: The content of this article does not constitute financial or investment advice.



