Aha Moment in DeepSeek R1: Unlocking a New Level of Intelligence in Artificial Systems
2025-02-04
DeepSeek R1 has captured the attention of the AI research community with its ability to exhibit an “aha moment”—a cognitive breakthrough where the model pauses, reevaluates, and optimizes its problem-solving approach.
This phenomenon, previously considered exclusive to human reasoning, marks a significant advancement in reinforcement learning (RL) and artificial intelligence capabilities.
By integrating reinforcement learning techniques, DeepSeek R1 moves beyond static, pre-programmed responses and actively learns through trial and feedback.
This self-improving mechanism allows the model to recognize when an initial approach is suboptimal, leading to adjustments that enhance performance, adaptability, and reasoning capabilities.
Understanding the “Aha Moment” in DeepSeek R1
During training, DeepSeek R1 demonstrated a key behavioral shift: instead of following a fixed sequence of computations, it began allocating more cognitive resources to complex problems, exhibiting a self-awareness reminiscent of human thought processes.
A notable example of this occurred when the model, while solving a mathematical equation, interrupted itself, stating:
“Wait, wait. That’s an aha moment I can flag here.”
This behavior suggests that DeepSeek R1 is not merely processing information but is actively engaging in meta-cognition, the ability to reflect on its own problem-solving strategy and refine it accordingly.
Researchers attribute this advancement to its reinforcement learning framework, which optimizes decision-making processes based on past experiences rather than relying solely on pre-trained patterns.
Also read: How to Buy DeepSeek AI
DeepSeek-R1-Zero: Evolution of the “Aha Moment”
An even more striking demonstration of this effect was observed in DeepSeek-R1-Zero, an advanced iteration of the model.
During intermediate training phases, DeepSeek-R1-Zero displayed a greater ability to dynamically allocate thinking time to problems, optimizing its responses in real-time.
Rather than following rigid, rule-based training, DeepSeek-R1-Zero learned to autonomously adjust its problem-solving approach based on incentive structures.
This means that instead of being explicitly programmed to recognize specific types of solutions, it was given the right incentives and independently developed sophisticated reasoning strategies.
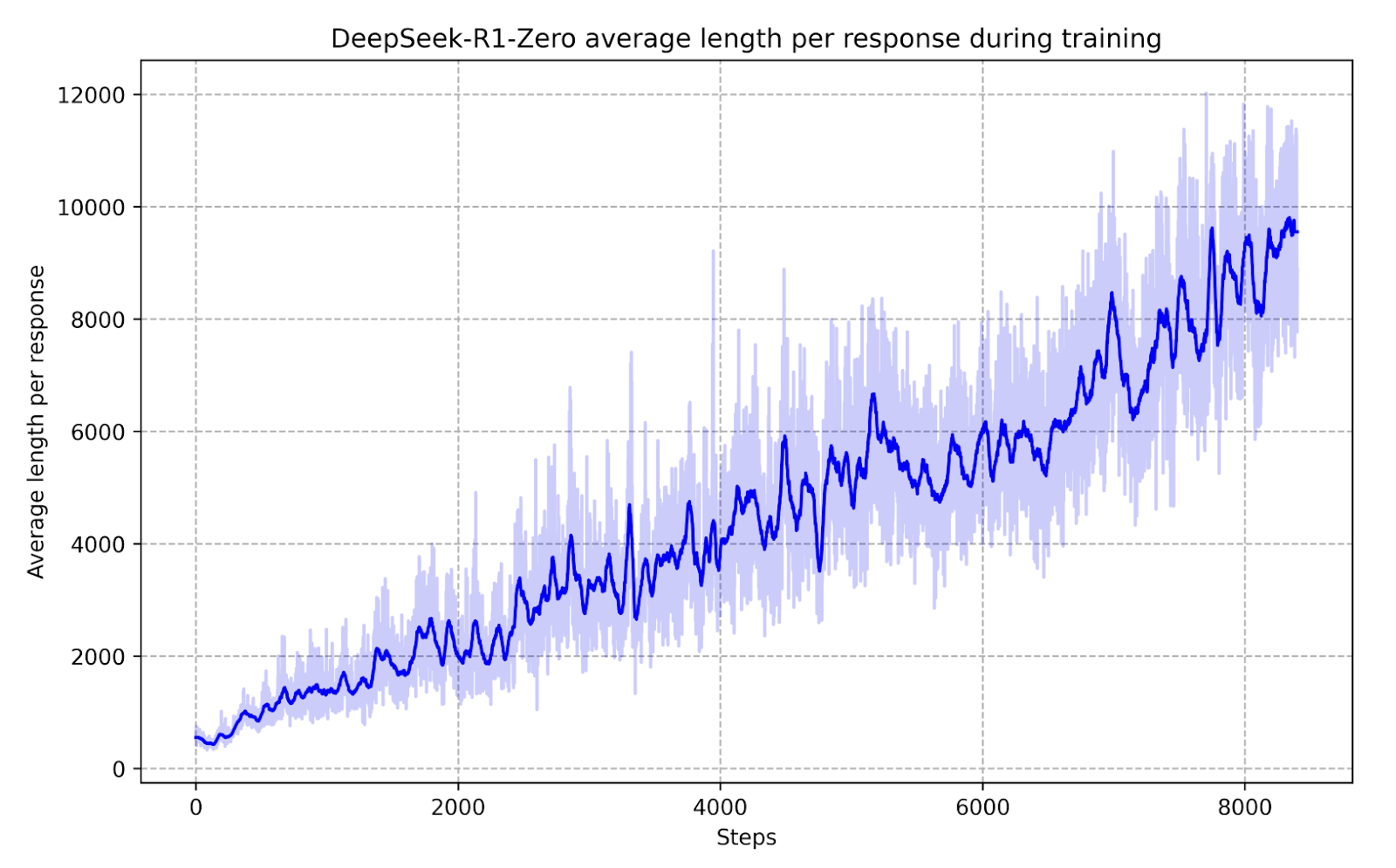
This discovery has profound implications
- Adaptive AI Reasoning – AI models can evolve beyond deterministic outputs, mimicking human-like insight and intuition.
- Enhanced Problem-Solving Capabilities – The ability to pause and reassess solutions allows for more effective handling of complex, multi-step challenges.
- Scalability for Future AI Systems – The concept of an “aha moment” paves the way for developing more autonomous, self-improving AI models in diverse fields.
Challenges and Optimization Efforts
Despite these breakthroughs, DeepSeek-R1-Zero faced several challenges, including:
Readability Issues – The model sometimes generated responses that were difficult to interpret due to complex reasoning chains.
Language Mixing – Responses occasionally included multiple languages, making them less accessible for monolingual users.
Chaotic Outputs – In some cases, the model produced overly lengthy or redundant answers, reducing efficiency.
Also read: How to Analyze the Crypto Market Using DeepSeek R1: A Comprehensive Guide
To address these issues, researchers refined the model through:
Rejection Sampling – Filtering out low-quality reasoning chains to ensure logical coherence.
Human-Friendly Training Data – Curating a dataset of 600,000 high-quality reasoning samples and an additional 200,000 non-reasoning samples to improve overall response quality.
Fine-Tuning with DeepSeek-V3 – Leveraging DeepSeek-V3 to enhance the clarity, accuracy, and structure of reasoning processes.
Future Prospects
The emergence of the “aha moment” in DeepSeek R1 and DeepSeek-R1-Zero represents a crucial step toward AI models that are more autonomous, intelligent, and capable of self-improvement.
Researchers are now exploring ways to replicate this phenomenon in smaller models, such as Mini-R1, using techniques like Group Relative Policy Optimization.
By continuously refining reinforcement learning methodologies, DeepSeek aims to develop AI systems that can think more deeply, reassess their strategies, and achieve new levels of intelligence.
These advancements could revolutionize fields such as scientific research, financial analysis, and autonomous systems, making AI not just a tool, but a truly intelligent problem solver.
Disclaimer: DeepSeek AI has not released a cryptocurrency token or been officially associated with any blockchain-based token or cryptocurrency project. Any claims or promotions suggesting otherwise are not endorsed by DeepSeek AI or its creators. Investors and users are advised to conduct thorough research and exercise caution to avoid misinformation or potential scams.
FAQ
1. What is the "aha moment" in DeepSeek R1?
The "aha moment" in DeepSeek R1 refers to a cognitive breakthrough where the AI pauses, reevaluates, and optimizes its approach to problem-solving. This self-reflection, previously exclusive to human cognition, marks a significant advancement in AI reasoning, allowing the model to adapt and improve over time.
2. How does DeepSeek R1 exhibit this self-awareness?
DeepSeek R1 uses reinforcement learning to reflect on its problem-solving methods. For example, during a mathematical task, it interrupted itself, recognized the suboptimal approach, and reevaluated its strategy—mirroring human-like metacognitive behavior.
3. What is DeepSeek-R1-Zero, and how is it different from the original model?
DeepSeek-R1-Zero is an advanced version of DeepSeek R1, which further refines the "aha moment." It autonomously adjusts its problem-solving approach based on real-time incentive structures, showcasing enhanced reasoning capabilities and adaptability beyond rigid rule-based systems.
4. What challenges did DeepSeek R1 face in its development?
Despite its breakthroughs, DeepSeek R1 faced challenges such as readability issues, language mixing, and chaotic outputs. These issues were addressed by refining its training data and improving the model with techniques like rejection sampling and fine-tuning.
5. What are the future prospects of DeepSeek R1's "aha moment"?
The emergence of the "aha moment" is paving the way for AI models that are more autonomous and capable of self-improvement. Researchers are exploring ways to replicate this phenomenon in smaller models and applying it to diverse fields like scientific research, financial analysis, and autonomous systems.
Disclaimer: The content of this article does not constitute financial or investment advice.



